Abstract
Vision-language models (VLMs) have become a common foundation for vision-and-language navigation in continuous environments (VLN-CE). Yet most VLM-based methods cast navigation as low-level action prediction, an interface that is ambiguous, tied to short-horizon motion primitives, and inefficient due to repeated VLM querying. We propose Goal2Pixel, a pure pixel-based paradigm that reformulates VLN-CE as navigable pixel grounding. Rather than predicting actions, Goal2Pixel uses the image plane as a unified spatial interface between VLM reasoning and robot motion: the model predicts a visible navigable pixel to the agent, which is back-projected into a 3D waypoint for forward navigation. For non-forward actions, we append auxiliary directive regions to the image plane, where the left/right/bottom regions are interpreted as turning left, turning right, and stopping, respectively. To enable long-horizon navigation, we propose a visibility-aware keyframe memory for compact and informative history representation. To adapt pretrained VLMs to navigable pixel grounding, we introduce semantic embeddings and coordinate-aware auxiliary losses. Goal2Pixel achieves competitive state-of-the-art performance while requiring fewer VLM inference calls than prior methods. On R2R-CE Val-Unseen it achieves 54.1% SR and 52.5% SPL with just 7.75 VLM calls per episode, 6× fewer than the 46.62 required by direct action prediction at 32.9% SR. The same trend holds on RxR-CE.
Contributions
- Goal2Pixel, a pure pixel-based interface that reformulates VLM-based VLN-CE from action prediction to image-space goal grounding.
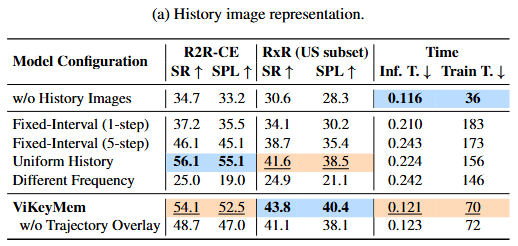
- ViKeyMem, a compact visibility-aware history representation that selects keyframes based on visibility change with trajectory overlays.
- Lightweight adaptations, including semantic embeddings and coordinate-aware auxiliary losses to improve navigable pixel grounding.
- Goal2Pixel achieves 54.1% / 52.5% on R2R-CE and 48.1% / 44.7% on RxR-CE in SR / SPL. Compared with direct action prediction, our pixel-based paradigm improves R2R-CE SR by 21.2% SR and reduces the average number of VLM calls by about 6x.
Method
Overview of the Go2Pixel architecture.
Real-World Experiments
16 real-world robot videos from resources/video/real_world. Each page shows a 2 by 2 grid.
R2R-CE Qualitative Videos
Reserved for 8 R2R videos from resources/video/r2r. Each page shows a 1 by 2 grid.
RxR-CE Qualitative Videos
Reserved for 8 RxR videos from resources/video/rxr. Each page shows a 1 by 2 grid.
Experimental Results
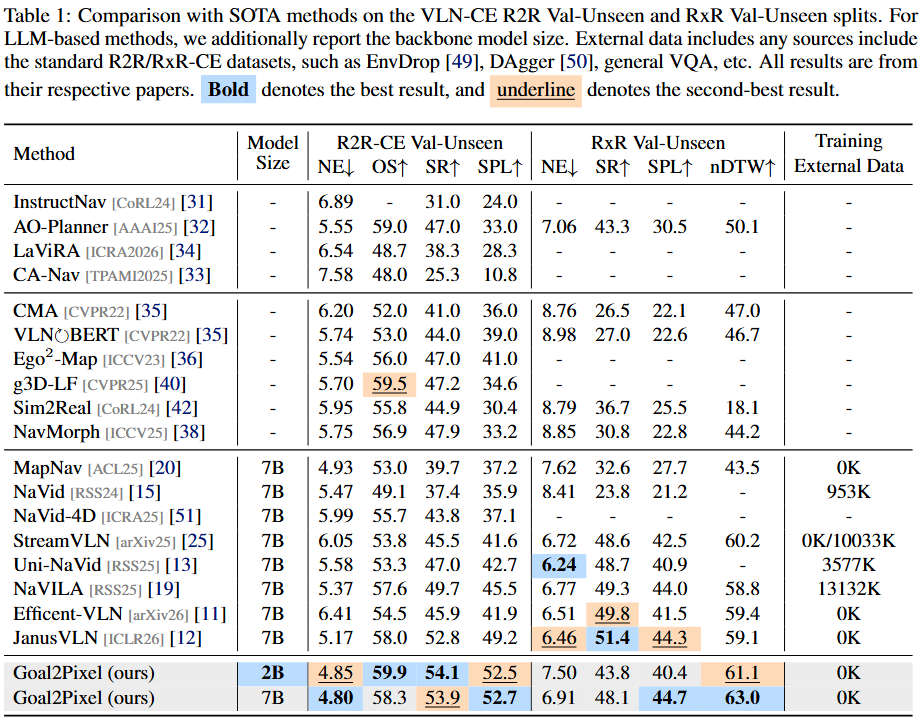
Ablation Studies
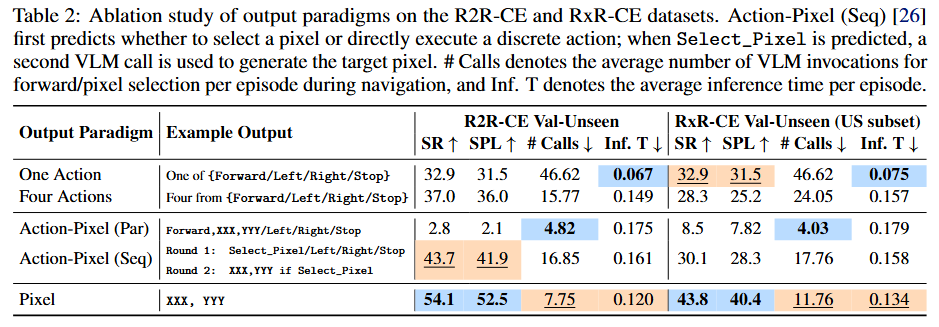
Output Paradigm
History Representation and ViKeyMem Visualization

Full ViKeyMem Visualization

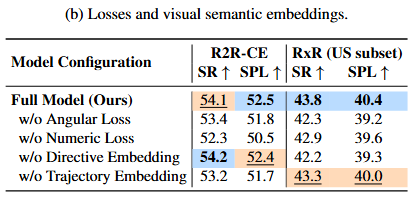
Component Ablation Study
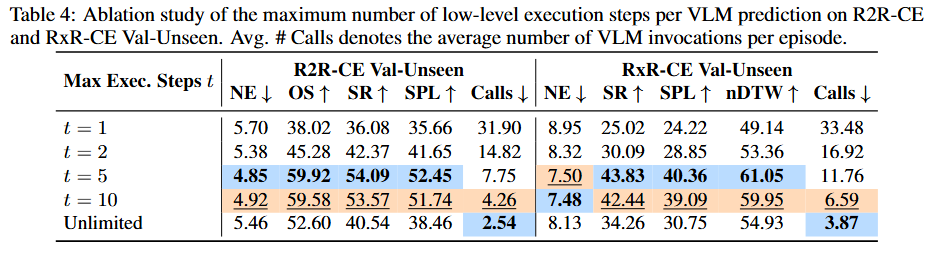
Maximum Number of Low-Level Execution Steps
Citation
@inproceedings{anonymous2026go2pixel,
title = {Goal2Pixel: Grounding Goals to Pixels for Vision-Language Navigation},
author = {Anonymous Author(s)},
booktitle = {Conference on Robot Learning},
year = {2026},
note = {Under review}
}